
Earlier this yr at SMX Advanced, I offered outcomes from our Peak Ace check lab. These assessments shed some mild on a number of technical implementation factors and the way Googlebot would cope with them.
One of my favourite assessments examined Google’s indexing of iFramed URLs and their content material. In my SMX Advanced presentation, I touched on numerous eventualities which will lead Google to index the content material inside an iFrame, whereas “assigning” that content material to its mum or dad URL.

The mum or dad URL can, in some cases, rank for content material that solely exists within the iFramed URL and never within the mum or dad URL.

Naturally, this excited individuals – and all kinds of follow-up questions arose. Here are a couple of of them with my solutions.
In the iFrame check, was the iFramed content material coming from the identical area or a distinct one?
My instance confirmed two URLs that dwell on the identical area: area.com/check.html would iFrame area.com/tobeframedA.html, in order that check.html may rank for content material that solely exists in tobeframedA.html.
The similar additionally works for externaldomain.com/tobeframedB.html – which may nonetheless trigger check.html to rank for content material solely current in tobeframedB.html, in addition to for iFrames residing on subdomains. We examined each mixture we may consider and concluded that it made no distinction the place the iFrame content material was hosted.
If you wish to forestall somebody from loading (and rating for) your content material in an iFrame, it could be a good suggestion to look into the X-Frame-Options Header. This signifies whether or not a browser must be allowed to render a web page in an iFrame.
If we had been to make use of iFrames with a no-indexed content material web page, would the mum or dad web page nonetheless rank for the listed content material with the intent to enhance web page velocity?
As quickly because the iFramed URL accommodates a meta robots noindex directive, the mum or dad URL received’t be capable of rank for the content material from the iFramed URL.

The similar is true in case you iFrame a URL that will be served with an X-Robots noindex header directive or is actively blocked utilizing robots.txt.
As far as web page velocity is anxious, iFrames assist the loading="lazy" attribute, which might defer offscreen iFrames from being loaded till a person scrolls close to them. This is a sublime resolution for rushing up loading occasions for URLs that depend upon iFramed content material.
Does Google give full worth to semi-hidden content material (content material that sometimes comes after ‘Read extra’)?
There doesn’t appear to be an excessive amount of love for utilizing “Read extra” performance throughout the ranks of Google. John Mueller went on file a few occasions right here and right here, questioning using the performance in its entirety. Mueller added, “I don’t assume you’d see a noticeable, direct change in SEO, […]”.
When we examined it, the aim of the check was to grasp what distinction the technical implementation may doubtlessly make – and if, generally, content material behind a “Read extra” could be listed (if accurately arrange).
The quick reply: whether or not or not it was seen, the content material could be listed, discovered and returned.
However, content material that was invisible throughout loading didn’t get highlighted within the snippet. The technical implementation didn’t make a distinction (so long as the content material was a part of the HTML DOM at load), leaving you free to make use of show:none, opacity:0, visibility:hidden, and so forth.
That mentioned, in my view, it’s inconceivable – attributable to numerous elements outdoors of our management – to create a check setup that (together with outcomes) may present an correct reply concerning the “full worth” a part of the query.
Did you point out that duplication in sure areas of the content material may be fastened by CSS implementation since it isn’t listed?
I did current some conduct that I discover pretty fascinating concerning CSS selectors. What technically occurs is that selectors corresponding to ::earlier than create a pseudo aspect that’s the first youngster of the chosen aspect. In apply, that is usually used so as to add beauty content material to an HTML aspect.
This is also helpful from an SEO viewpoint as a result of Googlebot appears to deal with this simply as it could deal with Chrome on desktop/smartphone. The rendered DOM stays unchanged (which is to be anticipated because it’s a pseudo class). As a end result, content material from inside mentioned selectors received’t be listed.
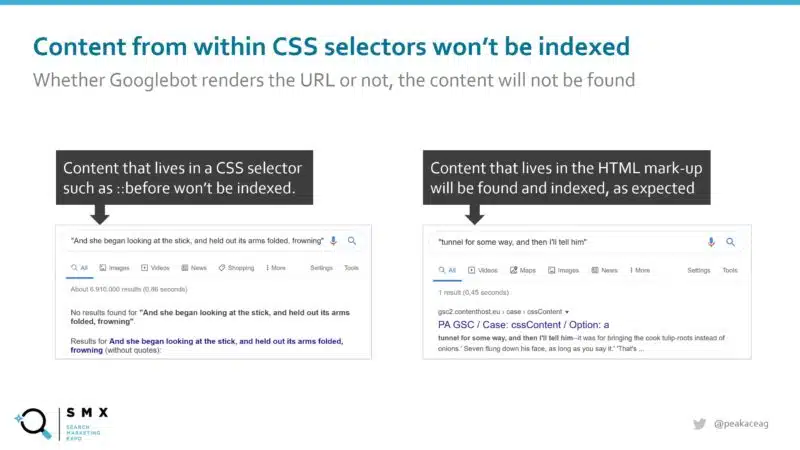
So, finally you could possibly use this to forestall sure content material from being listed with out protecting it from being displayed on the web site. Maybe you must show sure content material that will get labeled as “boilerplate” (e.g., delivery data, or authorized data) otherwise you wish to create a sure content material footprint. This opens up an important many prospects to discover additional.
Watch: Technical SEO testing in 2022: Separating reality from fiction
Below is the whole video of my SMX Advanced presentation.
Opinions expressed on this article are these of the visitor creator and never essentially Search Engine Land. Staff authors are listed here.
New on Search Engine Land
About The Author

Bastian Grimm is the CEO of Peak Ace and a famend skilled in large-scale, worldwide SEO, managing websites of just about any dimension and in extremely aggressive industries.
With greater than 20 years’ expertise in on-line advertising, technical and international SEO, Bastian was named “Search Personality of the Year” on the 2019 European Search Awards: a welcome acknowledgement of his contributions to a quickly evolving trade.
Bastian’s believes that understanding a goal market means not solely attending to grips with the language, but in addition the tradition. This has given him a singular perspective on tips on how to attain international audiences. Bastian leads a thriving staff of skilled native audio system, geared up to serve purchasers in 25+ languages, and the outcomes converse for themselves.
With a technology-driven strategy, Peak Ace is a one-stop store for extremely versatile, data-driven options for all related digital advertising channels. Working carefully with world-renowned manufacturers corresponding to Airbnb, TUI, Sage and McKinsey & Company, Peak Ace can be celebrated within the advertising trade. In 2022, Peak Ace was recognised for its distinctive customary as an company a number of occasions, named Best Large Integrated Agency by a number of trade awards our bodies. Bastian is proud to guide such an progressive, ever-expanding firm. His secret? Dynamic, decisive processes, an outstanding staff and at all times going to mattress with “inbox zero”.



