
Search engine crawl knowledge discovered inside log recordsdata is a implausible supply of knowledge for any SEO skilled.
By analyzing log files, you may achieve an understanding of precisely how search engines like google are crawling and decoding your web site – readability you merely can’t get when relying upon third-party instruments.
This will permit you to:
- Validate your theories by offering indeniable proof of how search engines like google are behaving.
- Prioritize your findings by serving to you to perceive the dimensions of an issue and the seemingly impression of fixing it.
- Uncover further points that aren’t seen when utilizing different knowledge sources.
But regardless of the multitude of advantages, log file knowledge isn’t used as regularly correctly. The causes are comprehensible:
- Accessing the information normally includes going by a dev crew, which may take time.
- The uncooked recordsdata could be large and supplied in an unfriendly format, so parsing the information takes effort.
- Tools designed to make the method simpler may have to be built-in earlier than the information could be piped to it, and the prices could be prohibitive.
Advertisement
Continue Reading Below
All of those points are completely legitimate limitations to entry, however they don’t have to be insurmountable.
With a little bit of primary coding information, you may automate the complete course of. That’s precisely what we’re going to do on this step-by-step lesson on utilizing Python to analyze server logs for SEO.
You’ll discover a script to get you began, too.
Initial Considerations
One of the largest challenges in parsing log file knowledge is the sheer variety of potential codecs. Apache, Nginx, and IIS supply a spread of various choices and permit customers to customise the information factors returned.
To complicate issues additional, many web sites now use CDN suppliers like Cloudflare, Cloudfront, and Akamai to serve up content material from the closest edge location to a person. Each of those has its personal codecs, as effectively.
We’ll give attention to the Combined Log Format for this put up, as that is the default for Nginx and a standard selection on Apache servers.
Advertisement
Continue Reading Below
If you’re not sure what kind of format you’re coping with, companies like Builtwith and Wappalyzer each present glorious details about an internet site’s tech stack. They may also help you establish this in the event you don’t have direct entry to a technical stakeholder.
Still none the wiser? Try opening one of many uncooked recordsdata.
Often, feedback are supplied with data on the particular fields, which may then be cross-referenced.
#Fields: time c-ip cs-method cs-uri-stem sc-status cs-version 17:42:15 172.16.255.255 GET /default.htm 200 HTTP/1.0
Another consideration is what search engines like google we would like to embrace, as this may want to be factored into our preliminary filtering and validation.
To simplify issues, we’ll give attention to Google, given its dominant 88% US market share.
Let’s get began.
1. Identify Files and Determining Formats
To carry out significant SEO evaluation, we would like a minimal of ~100k requests and 2-4 weeks’ price of information for the typical web site.
Due to the file sizes concerned, logs are normally break up into particular person days. It’s nearly assured that you simply’ll obtain a number of recordsdata to course of.
As we don’t know what number of recordsdata we’ll be coping with except we mix them earlier than working the script, an essential first step is to generate an inventory of the entire recordsdata in our folder utilizing the glob module.
This permits us to return any file matching a sample that we specify. As an instance, the next code would match any TXT file.
import glob
recordsdata = glob.glob('*.txt')
Log recordsdata could be supplied in quite a lot of file codecs, nonetheless, not simply TXT.
In reality, at instances the file extension will not be one you acknowledge. Here’s a uncooked log file from Akamai’s Log Delivery Service, which illustrates this completely:
bot_log_100011.esw3c_waf_S.202160250000-2000-41
Additionally, it’s attainable that the recordsdata obtained are break up throughout a number of subfolders, and we don’t need to waste time copying these right into a singular location.
Thankfully, glob helps each recursive searches and wildcard operators. This signifies that we will generate an inventory of all of the recordsdata inside a subfolder or little one subfolders.
Advertisement
Continue Reading Below
recordsdata = glob.glob('**/*.*', recursive=True)
Next, we would like to establish what varieties of recordsdata are inside our record. To do that, the MIME type of the particular file could be detected. This will inform us precisely what kind of file we’re coping with, whatever the extension.
This could be achieved utilizing python-magic, a wrapper across the libmagic C library, and making a easy operate.
pip set up python-magic pip set up libmagic
import magic
def file_type(file_path):
mime = magic.from_file(file_path, mime=True)
return mime
List comprehension can then be used to loop by our recordsdata and apply the operate, making a dictionary to retailer each the names and kinds.
file_types = [file_type(file) for file in files] file_dict = dict(zip(recordsdata, file_types))
Finally, a operate and a while loop to extract an inventory of recordsdata that return a MIME kind of textual content/plain and exclude the rest.
uncompressed = []
def file_identifier(file):
for key, worth in file_dict.objects():
if file in worth:
uncompressed.append(key)
whereas file_identifier('textual content/plain'):
file_identifier('textual content/plain') in file_dict

2. Extract Search Engine Requests
After filtering down the recordsdata in our folder(s), the subsequent step is to filter the recordsdata themselves by solely extracting the requests that we care about.
Advertisement
Continue Reading Below
This removes the necessity to mix the recordsdata utilizing command-line utilities like GREP or FINDSTR, saving an inevitable 5-10 minute search by open pocket book tabs and bookmarks to discover the right command.
In this occasion, as we solely need Googlebot requests, looking for ‘Googlebot’ will match the entire relevant user agents.
We can use Python’s open operate to learn and write our file and Python’s regex module, RE, to carry out the search.
import re
sample = 'Googlebot'
new_file = open('./googlebot.txt', 'w', encoding='utf8')
for txt_files in uncompressed:
with open(txt_files, 'r', encoding='utf8') as text_file:
for line in text_file:
if re.search(sample, line):
new_file.write(line)
Regex makes this simply scalable utilizing an OR operator.
sample = 'Googlebot|bingbot'
3. Parse Requests
In a previous post, Hamlet Batista supplied steering on how to use regex to parse requests.
As an alternate method, we’ll be utilizing Pandas‘ highly effective inbuilt CSV parser and a few primary knowledge processing capabilities to:
- Drop pointless columns.
- Format the timestamp.
- Create a column with full URLs.
- Rename and reorder the remaining columns.
Rather than hardcoding a site identify, the input operate can be utilized to immediate the person and save this as a variable.
Advertisement
Continue Reading Below
whole_url = enter('Please enter full area with protocol: ') # get area from person enter
df = pd.read_csv('./googlebot.txt', sep='s+', error_bad_lines=False, header=None, low_memory=False) # import logs
df.drop([1, 2, 4], axis=1, inplace=True) # drop undesirable columns/characters
df[3] = df[3].str.exchange('[', '') # split time stamp into two
df[['Date', 'Time']] = df[3].str.break up(':', 1, increase=True)
df[['Request Type', 'URI', 'Protocol']] = df[5].str.break up(' ', 2, increase=True) # break up uri request into columns
df.drop([3, 5], axis=1, inplace=True)
df.rename(columns = {0:'IP', 6:'Status Code', 7:'Bytes', 8:'Referrer URL', 9:'User Agent'}, inplace=True) #rename columns
df['Full URL'] = whole_url + df['URI'] # concatenate area identify
df['Date'] = pd.to_datetime(df['Date']) # declare knowledge sorts
df[['Status Code', 'Bytes']] = df[['Status Code', 'Bytes']].apply(pd.to_numeric)
df = df[['Date', 'Time', 'Request Type', 'Full URL', 'URI', 'Status Code', 'Protocol', 'Referrer URL', 'Bytes', 'User Agent', 'IP']] # reorder columns
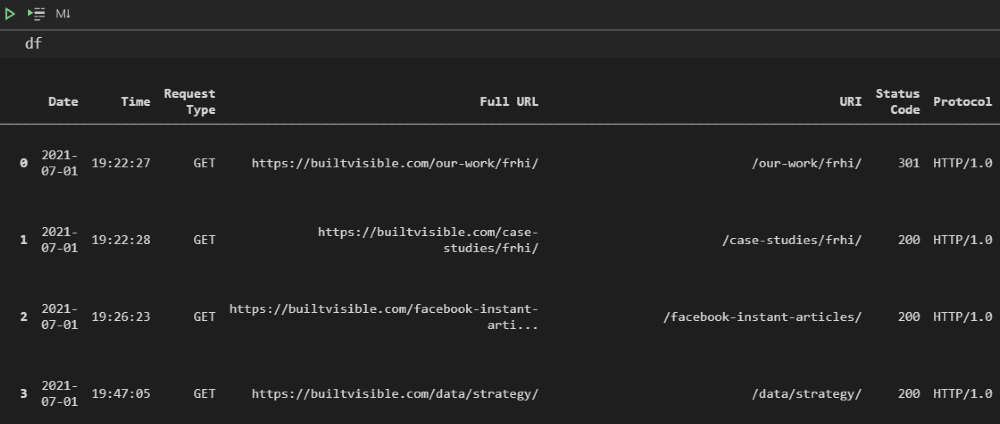
4. Validate Requests
It’s extremely straightforward to spoof search engine person brokers, making request validation an important a part of the method, lest we find yourself drawing false conclusions by analyzing our personal third-party crawls.
To do that, we’re going to set up a library referred to as dnspython and carry out a reverse DNS.
Pandas can be utilized to drop duplicate IPs and run the lookups on this smaller DataBody, earlier than reapplying the outcomes and filtering out any invalid requests.
Advertisement
Continue Reading Below
from dns import resolver, reversename
def reverseDns(ip):
strive:
return str(resolver.question(reversename.from_address(ip), 'PTR')[0])
besides:
return 'N/A'
logs_filtered = df.drop_duplicates(['IP']).copy() # create DF with dupliate ips filtered for examine
logs_filtered['DNS'] = logs_filtered['IP'].apply(reverseDns) # create DNS column with the reverse IP DNS outcome
logs_filtered = df.merge(logs_filtered[['IP', 'DNS']], how='left', on=['IP']) # merge DNS column to full logs matching IP
logs_filtered = logs_filtered[logs_filtered['DNS'].str.accommodates('googlebot.com')] # filter to verified Googlebot
logs_filtered.drop(['IP', 'DNS'], axis=1, inplace=True) # drop dns/ip columns
Taking this method will drastically velocity up the lookups, validating thousands and thousands of requests in minutes.
In the instance beneath, ~4 million rows of requests had been processed in 26 seconds.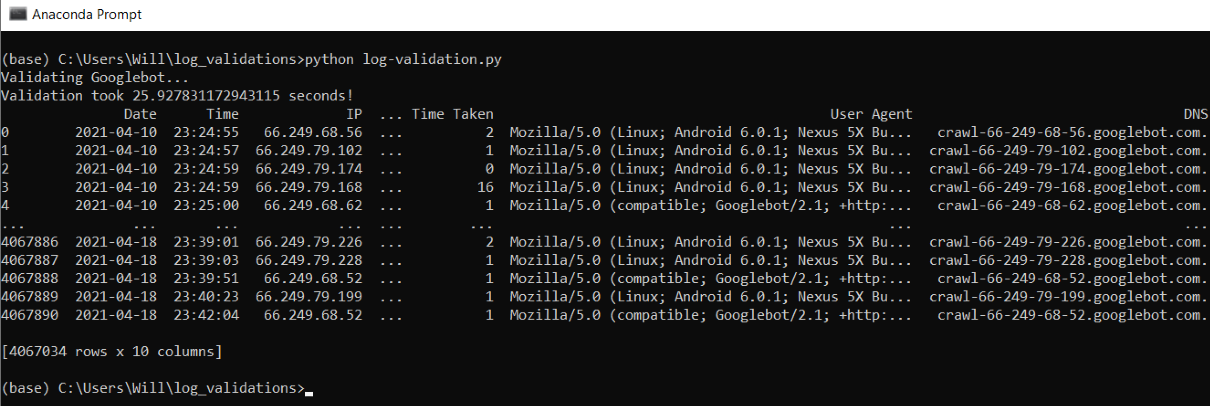
5. Pivot the Data
After validation, we’re left with a cleansed, well-formatted knowledge set and might start pivoting this knowledge to extra simply analyze knowledge factors of curiosity.
First off, let’s start with some easy aggregation utilizing Pandas’ groupby and agg capabilities to carry out a depend of the variety of requests for totally different standing codes.
Advertisement
Continue Reading Below
status_code = logs_filtered.groupby('Status Code').agg('measurement')
To replicate the kind of depend you might be used to in Excel, it’s price noting that we want to specify an mixture operate of ‘measurement’, not ‘depend’.
Using depend will invoke the operate on all columns throughout the DataBody, and null values are dealt with otherwise.
Resetting the index will restore the headers for each columns, and the latter column could be renamed to one thing extra significant.
status_code = logs_filtered.groupby('Status Code').agg('measurement').sort_values(ascending=False).reset_index()
status_code.rename(columns={0:'# Requests'}, inplace=True)
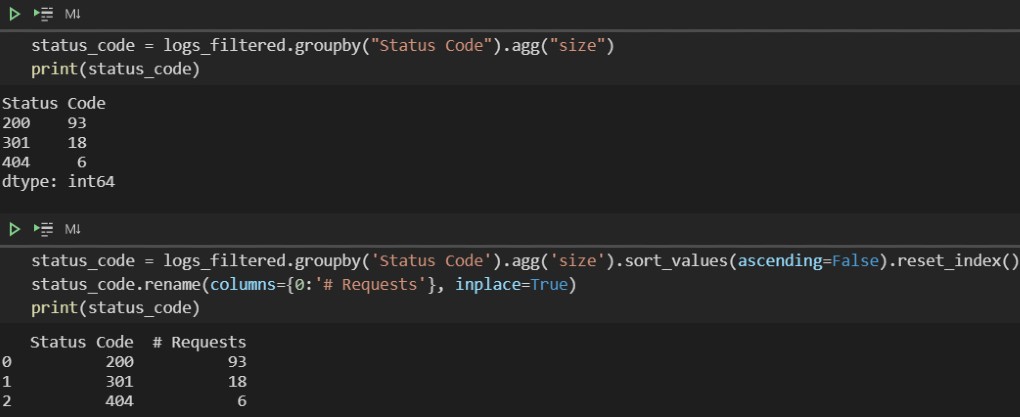
For extra superior knowledge manipulation, Pandas’ inbuilt pivot tables supply performance comparable to Excel, making complicated aggregations attainable with a singular line of code.
At its most elementary degree, the operate requires a specified DataBody and index – or indexes if a multi-index is required – and returns the corresponding values.
Advertisement
Continue Reading Below
pd.pivot_table(logs_filtered, index['Full URL'])
For better specificity, the required values could be declared and aggregations – sum, imply, and many others – utilized utilizing the aggfunc parameter.
Also price mentioning is the columns parameter, which permits us to show values horizontally for clearer output.
status_code_url = pd.pivot_table(logs_filtered, index=['Full URL'], columns=['Status Code'], aggfunc="measurement", fill_value=0)
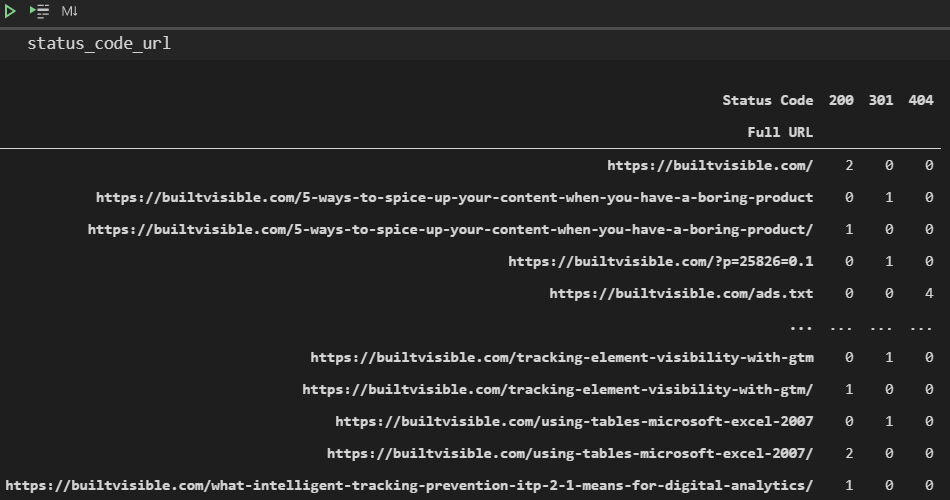
Here’s a barely extra complicated instance, which gives a depend of the distinctive URLs crawled per person agent per day, reasonably than only a depend of the variety of requests.
user_agent_url = pd.pivot_table(logs_filtered, index=['User Agent'], values=['Full URL'], columns=['Date'], aggfunc=pd.Series.nunique, fill_value=0)
If you’re nonetheless fighting the syntax, try Mito. It permits you to work together with a visible interface inside Jupyter when utilizing JupyterLab, however nonetheless outputs the related code.
Advertisement
Continue Reading Below
Incorporating Ranges
For knowledge factors like bytes that are seemingly to have many alternative numerical values, it is sensible to bucket the information.
To achieve this, we will outline our intervals inside an inventory after which use the cut operate to kind the values into bins, specifying np.inf to catch something above the utmost worth declared.
byte_range = [0, 50000, 100000, 200000, 500000, 1000000, np.inf]
bytes_grouped_ranges = (logs_filtered.groupby(pd.reduce(logs_filtered['Bytes'], bins=byte_range, precision=0))
.agg('measurement')
.reset_index()
)
bytes_grouped_ranges.rename(columns={0: '# Requests'}, inplace=True)
Interval notation is used throughout the output to outline actual ranges, e.g.
(50000 100000]
The spherical brackets point out when a quantity is not included and a sq. bracket when it’s included. So, within the above instance, the bucket accommodates knowledge factors with a price of between 50,001 and 100,000.
6. Export
The remaining step in our course of is to export our log knowledge and pivots.
For ease of research, it is sensible to export this to an Excel file (XLSX) reasonably than a CSV. XLSX recordsdata assist a number of sheets, which signifies that all of the DataFrames could be mixed in the identical file.
This could be achieved utilizing to excel. In this case, an ExcelWriter object additionally wants to be specified as a result of multiple sheet is being added into the identical workbook.
Advertisement
Continue Reading Below
author = pd.ExcelAuthor('logs_export.xlsx', engine="xlsxwriter", datetime_format="dd/mm/yyyy", choices={'strings_to_urls': False})
logs_filtered.to_excel(author, sheet_name="Master", index=False)
pivot1.to_excel(author, sheet_name="My pivot")
author.save()
When exporting a lot of pivots, it helps to simplify issues by storing DataFrames and sheet names in a dictionary and utilizing a for loop.
sheet_names = {
'Request Status Codes Per Day': status_code_date,
'URL Status Codes': status_code_url,
'User Agent Requests Per Day': user_agent_date,
'User Agent Requests Unique URLs': user_agent_url,
}
for sheet, identify in sheet_names.objects():
identify.to_excel(author, sheet_name=sheet)
One final complication is that Excel has a row restrict of 1,048,576. We’re exporting each request, so this might trigger issues when coping with massive samples.
Because CSV recordsdata haven’t any restrict, an if assertion could be employed to add in a CSV export as a fallback.
If the size of the log file DataBody is larger than 1,048,576, this may as a substitute be exported as a CSV, stopping the script from failing whereas nonetheless combining the pivots right into a singular export.
if len(logs_filtered) <= 1048576:
logs_filtered.to_excel(author, sheet_name="Master", index=False)
else:
logs_filtered.to_csv('./logs_export.csv', index=False)
Final Thoughts
The further insights that may be gleaned from log file knowledge are effectively price investing a while in.
If you’ve been avoiding leveraging this knowledge due to the complexities concerned, my hope is that this put up will persuade you that these could be overcome.
For these with entry to instruments already who're occupied with coding, I hope breaking down this course of end-to-end has given you a better understanding of the issues concerned when creating a bigger script to automate repetitive, time-consuming duties.
Advertisement
Continue Reading Below
The full script I created could be discovered right here on Github.
This contains further extras similar to GSC API integration, extra pivots, and assist for two extra log codecs: Amazon ELB and W3C (utilized by IIS).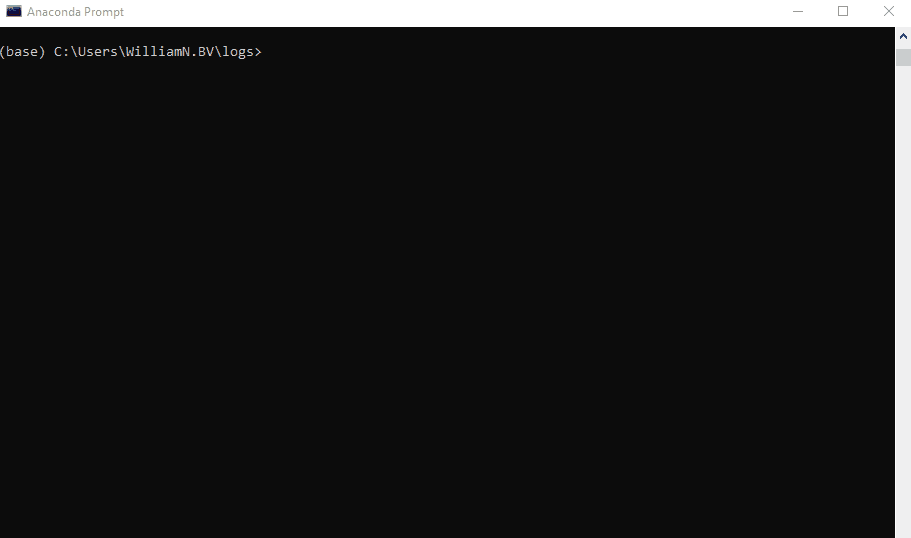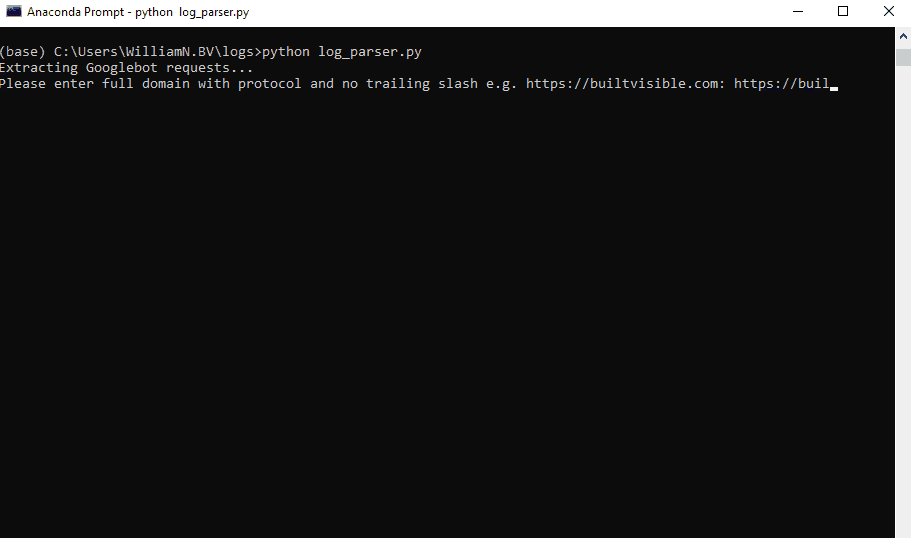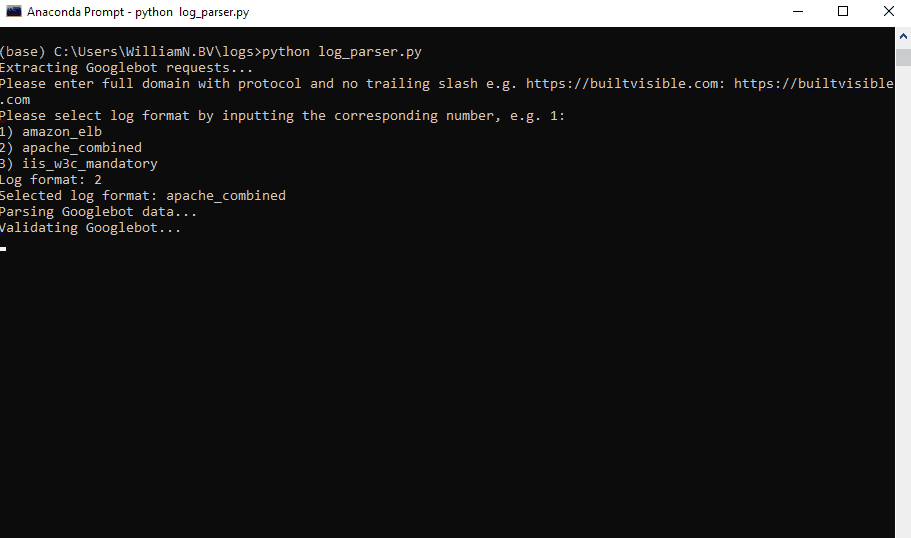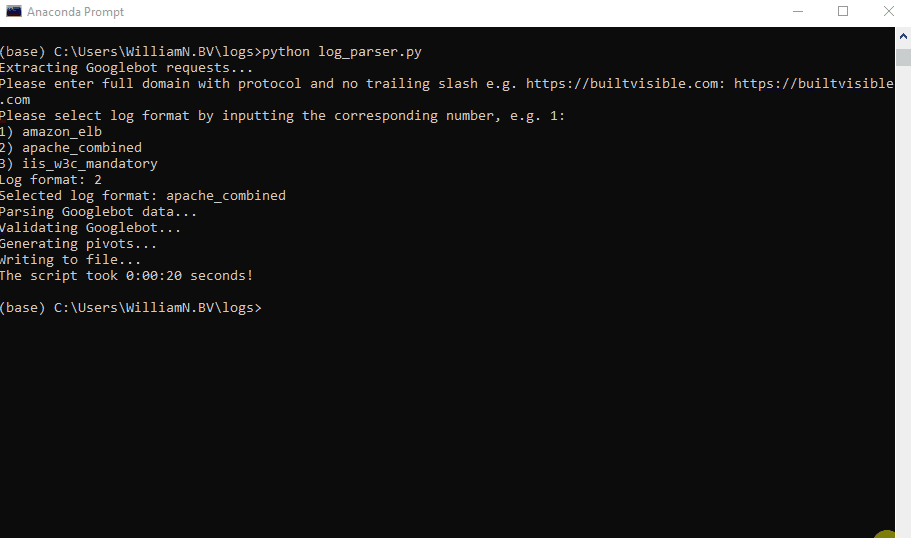
To add in one other format, embrace the identify throughout the log_fomats record on line 17 and add an extra elif assertion on line 193 (or edit one of many present ones).
There is, in fact, huge scope to increase this additional. Stay tuned for an element two put up that may cowl the incorporation of information from third-party crawlers, more advanced pivots, and knowledge visualization.
Advertisement
Continue Reading Below
More Resources:
Image Credits
All screenshots taken by creator, July 2021



